
Production Operations: Monitoring, SLAs, and “Fail-Closed” Without Bricking Your App
A zero-knowledge identity integration can be cryptographically flawless and mathematically perfect. It can also be operationally disastrous.
The outage problem most teams discover too late is that cryptographic correctness does not guarantee operational availability. If your verifier stack cannot reach a revocation oracle, or if an API gateway suffers from severe latency, the system stops. If it stops incorrectly, you either accept illicit transactions by failing open, or you block legitimate revenue by failing closed too aggressively.
Your decentralized proof system is critical business infrastructure. How do you fail safely and compliantly without stopping your entire business? This playbook explains how to engineer graceful degradation, define actionable SLAs, and maintain audit evidence continuity when the inevitable service outages occur.
The 30-Second Map: how a proof system behaves in production
In production, a proof request moves through a multi-layer process much like a production line. Each layer has its own machine states, failure modes, and monitoring signals.
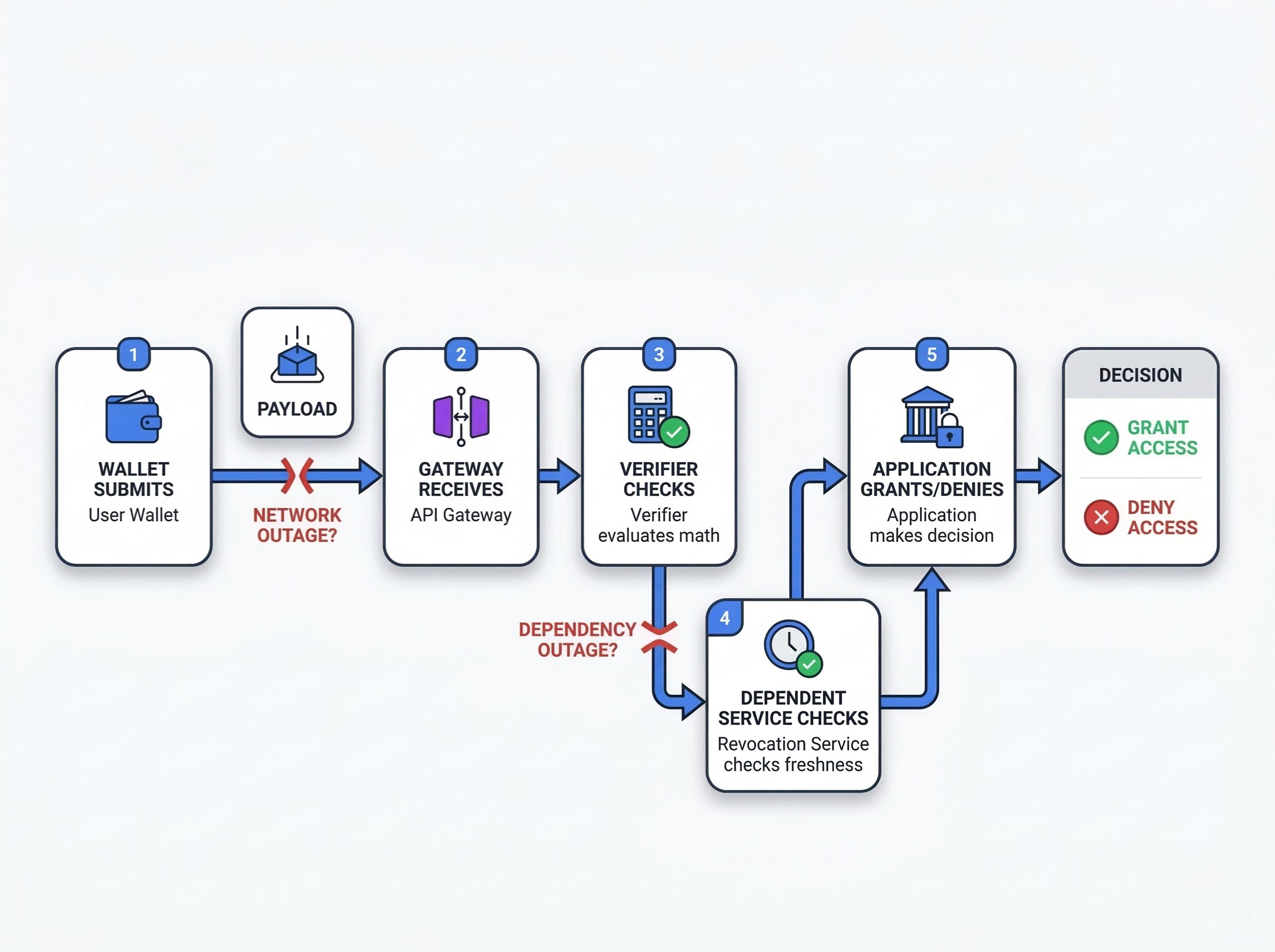
The proof pipeline as a production process. The user’s wallet submits a payload. The API gateway receives it. The verifier evaluates the math. A dependent service checks revocation freshness. Finally, the application grants or denies access.
Where outages actually happen. Outages rarely happen because the math breaks. They happen because network boundaries fail, edge devices lose connectivity, databases lock, or third-party issuers experience unplanned downtime.
What “fail-closed” should and should not mean. Failing closed means rejecting a request when compliance cannot be verified. It should not mean crashing the entire application or trapping user funds because a secondary dependency timed out.
Production operations monitoring: what you must see in real time
To maintain consistent product quality, you need visibility. Production operations monitoring for a proof system requires tracking specific signals that dictate compliance health.
Latency, proof failures, and revocation fetch health. Operators must monitor the latency of the verification circuit. They must track the ratio of mathematically invalid proofs to valid ones. Crucially, they must monitor revocation fetch health—how long has it been since the verifier successfully pulled a fresh status root?
Queue depth, timeout rates, and dependency health. If requests are queuing at the verifier, or if timeout rates spike when contacting an external trust registry, the system is degrading.
Machine states for each service layer. Every microservice in the proof pipeline must report its health. Operators need shop floor visibility into machine states, except here the machines are proof services, revocation endpoints, queues, and verification workers.
User-visible symptoms vs infrastructure symptoms. A spike in 400-level errors usually means wallets are generating bad proofs (a user or client issue). A spike in 500-level errors means your verifier or a dependent service is failing (an infrastructure issue). Real time production monitoring must separate these signals immediately.
Building a production monitoring system that supports safe decisions
A useful production monitoring system does more than create dashboards; it helps operators define thresholds, identify inefficiencies, and make informed decisions under pressure.
Define your critical signals. Do not track everything. Focus on the golden signals: latency, traffic volume, error rates, and system saturation.
Separate leading indicators from lagging indicators. Queue depth is a leading indicator of a failure. Increased customer support tickets complaining about failed logins is a lagging indicator.
Structured data, reports, and alert quality. Logs must use structured data (like JSON). This matters because post-incident reports require querying specific policy IDs or dependency states.
Real time data collection across the stack. Real time data collection must aggregate metrics from the frontend client, the API gateway, the verifier, and the backend application to provide a complete picture of the verification process.
Real time production monitoring without alert fatigue
Real time production monitoring must distinguish transient noise from actual incidents. If an alert fires every time a single proof fails, operators will ignore the system.
What operators need every minute. Operators need actionable insights. They need alerts triggered only by sustained threshold breaches, such as revocation freshness exceeding 15 minutes, or verification latency doubling for more than 60 seconds.
What production managers need every shift. Production managers need aggregated shift reports showing overall equipment effectiveness, API uptime, and the percentage of requests processed within latency targets.
What leadership needs in service level agreement reports. Leadership needs high-level performance metrics summarizing compliance availability, service provider SLA adherence, and the business impact of any service outages.
Service level agreement design for proof-dependent systems
A service level agreement (SLA) for an identity system is fundamentally different from a standard web API SLA.
What a service level agreement should measure. Uptime is insufficient. A compliance SLA must measure availability, latency, revocation freshness, and evidence continuity. If the verifier is "up" but cannot fetch revocation data, the system is operationally down.
Good faith degradation vs true fail-closed enforcement. The SLA must define what happens during a partial outage. Will the system operate in a degraded mode in good faith, or will it strictly fail-closed?
What to demand from each service provider. If you rely on external issuers or decentralized oracle networks, your contracts must define strict availability targets and maximum acceptable latency for status updates.
Graceful degradation vs fail-closed: where to draw the line
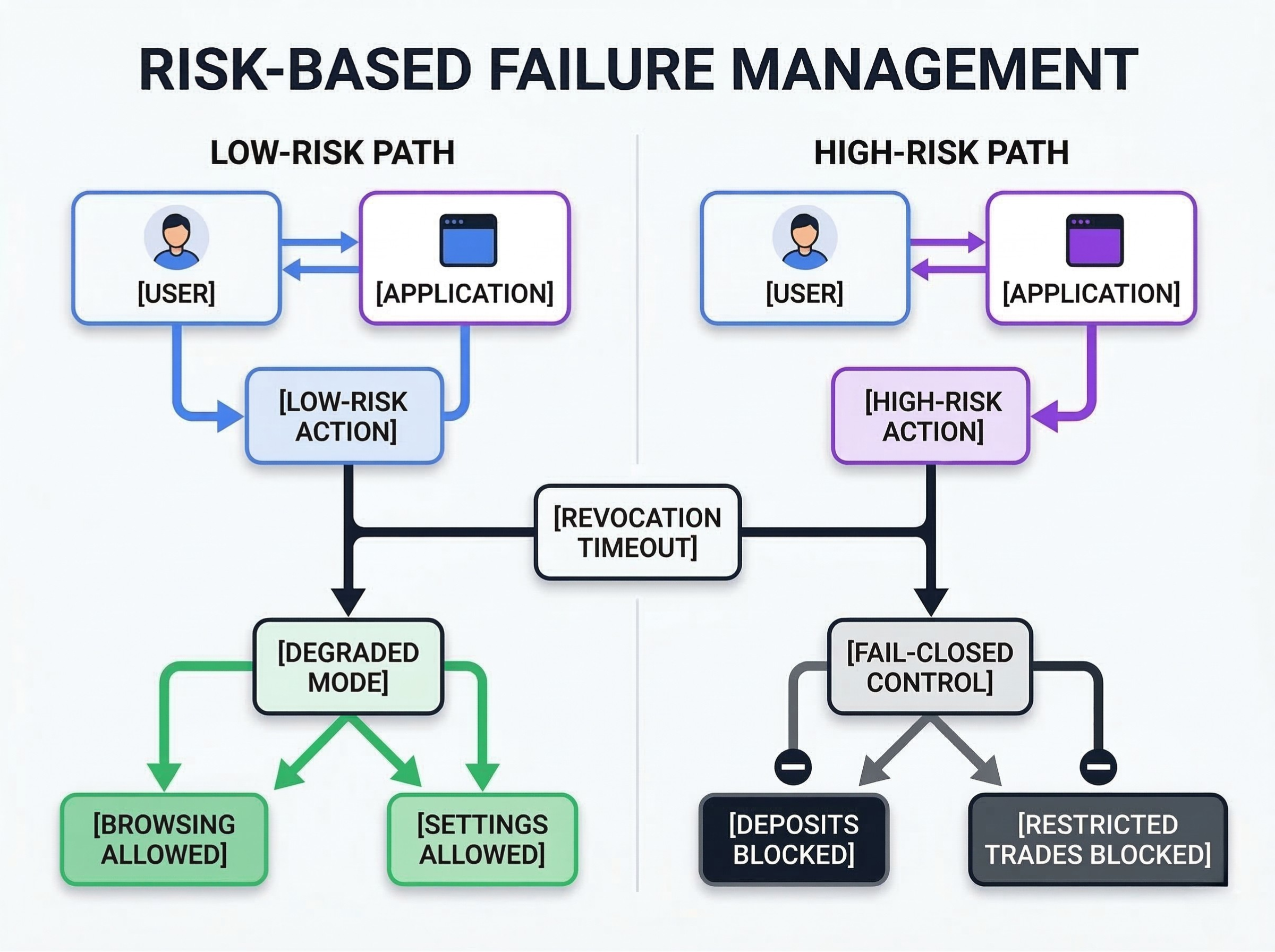
The key is to define, in advance and in context, which failures require the system to stop and which allow the team to react quickly without compromising the critical control.
When degraded mode is acceptable. If a user attempts to read a premium article or access a low-risk forum, and the revocation service times out, a brief degraded mode might be acceptable to meet customer demand and maintain customer satisfaction.
When the system must stop. If a user attempts to withdraw $100,000 or trade a restricted security token, and the revocation service times out, the system must fail-closed. Regulatory compliance requires absolute certainty for high-risk financial transactions.
How to protect the business without blocking everything. You protect the business by scoping the failure. One layer can degrade while another stays strict. A platform might allow users to browse yields and manage their account settings (degraded mode) while explicitly blocking new deposits (fail-closed).
Circuit breakers, retries, and dependency boundaries
When a service provider fails, your application must protect itself. [Citation: Standard Site Reliability Engineering (SRE) practices for distributed systems].
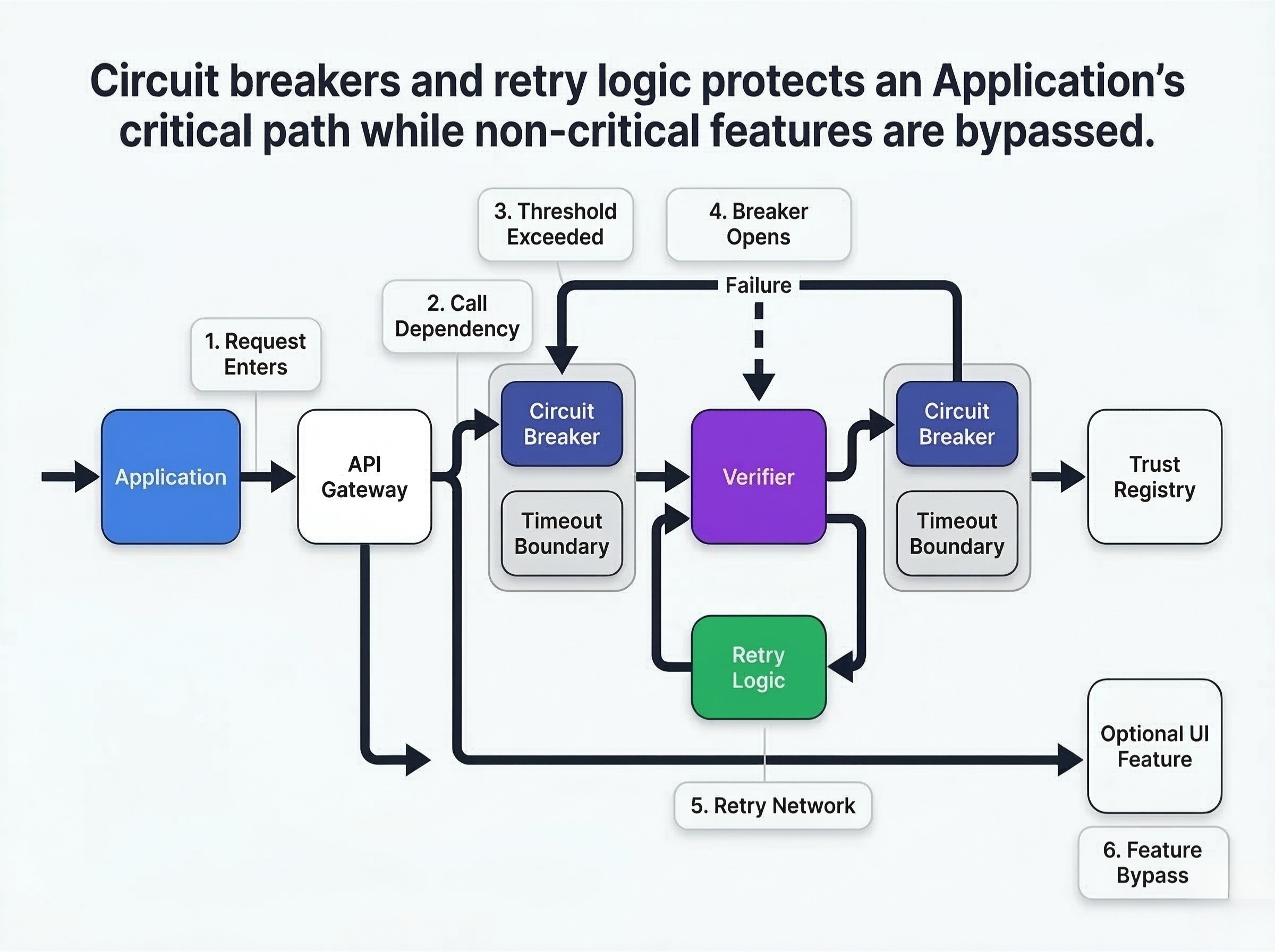
How to define circuit breaker thresholds. Implement circuit breakers between your application and the verifier, and between the verifier and the trust registry. If error rates exceed a defined threshold (e.g., 5% over 10 seconds), the circuit breaker opens, halting requests to the failing service.
What to stop automatically. Stop sending requests to a completely unresponsive endpoint. This prevents your own application threads from exhausting while waiting for timeouts.
What to retry. Retry transient network failures using exponential backoff with jitter. Do not retry cryptographic validation failures; if the math fails once, it will fail again.
What to bypass temporarily. If a non-critical feature (like an optional UI badge) relies on a failing identity service, bypass it temporarily to keep the core application running.
Why cascading failures break more than the proof flow. If your application synchronously waits for a slow verifier without a timeout, your entire backend will eventually lock up. Define strict dependency boundaries.
Production monitoring tools and edge devices: what to instrument
To react quickly and solve problems, you need accurate tracking across your distributed infrastructure.
API gateways, verifiers, queues, and revocation services. Instrument every internal hop. Track how long a request sits in a queue versus how long it spends executing in the verifier circuit.
Wallet flows and client-side telemetry. Monitor the client side. If users are abandoning the flow during proof generation, your cycle time is too high, or the mobile device lacks the computational power required.
Edge devices, regional nodes, and network boundaries. In distributed environments, edge devices and regional gateways play the role that equipment does on a shop floor: if you cannot observe their health, plant level visibility disappears.
Accurate tracking across distributed infrastructure. Ensure every proof request receives a unique correlation ID at the edge device, and pass that ID through every subsequent service layer for accurate, end-to-end tracing.
Audit evidence continuity during downtime
A compliance system must leave an auditable trail, even when it is failing.
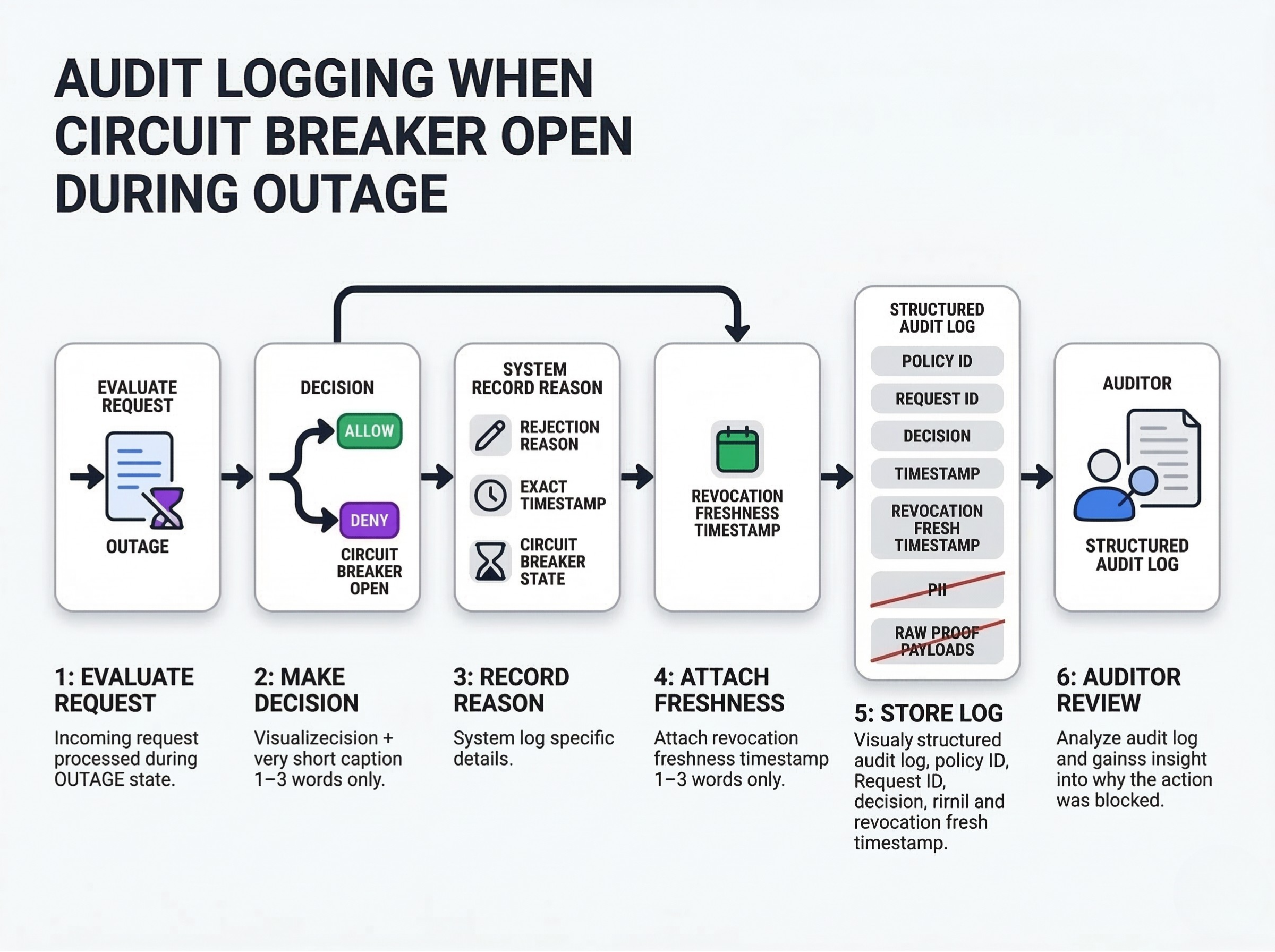
Preserve logs, decision context, and timestamps. If a circuit breaker opens and a request is rejected, the system must log the rejection reason, the exact timestamp, and the state of the circuit breaker.
Keep reports usable after service outages. You must be able to prove to an auditor why a transaction was blocked during an outage. "The system was down" is not an acceptable compliance record.
How to create evidence packs when parts of the system are unavailable. Log the policy ID, the request ID, the decision (allow/deny), and the freshness timestamp of the last known good revocation root. Never log Personally Identifiable Information (PII) or raw proof payloads, even in debug mode.
CTO Checklist: the fail-safe operations baseline
Use this checklist to ensure your production operations meet industry best practices.
- Monitoring checklist: Define and alert on latency, error rates, and revocation freshness thresholds using your production monitoring tools.
- SLA checklist: Establish a service level agreement that explicitly covers dependency freshness, not just API uptime.
- Incident runbook checklist: Document the exact steps operators must take when a third-party service provider experiences unplanned downtime.
- Evidence continuity checklist: Verify that structured data logs capture the decision context and timestamps for every rejected request during an outage.
Example 1: revocation endpoint outage during peak traffic
The scenario: During peak customer demand, the external trust registry goes offline. The verifier can no longer fetch fresh status roots.
The operational response: Real time production monitoring detects the stale root after 5 minutes. An alert fires. The circuit breaker for the revocation fetcher opens.
The business impact: Following the runbook, the system enters a degraded state. High-risk actions (deposits) fail-closed. Low-risk actions (browsing) remain available. The system preserves audit evidence showing exactly which transactions were blocked due to the stale dependency.
Example 2: proof verification latency spike that threatens customer experience
The scenario: An unexpected surge in complex proof submissions saturates the verifier CPU capacity. Latency spikes from 200ms to 4 seconds. Customer expectations are not being met.
The operational response: The production monitoring system detects the latency breach. The API gateway automatically begins rate-limiting incoming requests based on a predefined token bucket algorithm.
The business impact: The system protects itself from a cascading failure. A subset of users experience slow load times, but the core application remains stable. Operators use the real time data to provision additional verifier instances and restore performance metrics.
Pitfalls, anti-patterns, and trade-offs
Failing closed everywhere. If your controls destroy cycle time and output during every minor fault, you are not keeping lines moving. Do not brick your entire application because a low-risk optional feature timed out.
Failing open by accident. If an API returns a 500 error, and the application interprets that as "continue," you have failed open. Default to deny for all restricted actions.
Measuring too much but tracking the wrong metrics. Tracking CPU temperature is noise; tracking proof verification latency is a critical signal. Focus on metrics that directly impact customer satisfaction and compliance integrity.
Ignoring customer demand and output expectations. The goal is not to mimic manufacturing operations literally, but the analogy is useful: an identity system must balance security with the ability to process the required throughput (takt time).
What matters vs what is noise
When evaluating production operations, separate actionable signals from vanity metrics.
| What Matters (Actionable) | What is Noise (Vanity) |
| Signal: Revocation freshness exceeds 10 minutes. | Noise: Total number of API requests per month. |
| Safe degradation: Blocking high-risk actions while allowing browsing. | Silent failure: Dropping requests without logging the rejection reason. |
| Audit evidence: Logging policy IDs, timestamps, and pass/fail results. | Incomplete logs: Logging generic "500 Server Error" messages. |
Best practices for continuous improvement in production operations
Operational excellence requires continuous improvement.
Use incidents to identify inefficiencies. Every outage is an opportunity to improve the system. Conduct blameless post-mortems to understand why the failure occurred and how the monitoring system can detect it faster next time.
Improve cycle time, response quality, and operator context. Refine your alerts and runbooks based on incident data. Ensure operators have the context they need to react quickly and confidently.
Turn monitoring data into actionable insights. Analyze long-term performance metrics to identify trends, predict capacity bottlenecks, and optimize the overall verification process for the future.
Conclusion
A decentralized proof system is only as reliable as its operational controls. By implementing robust real time production monitoring, defining clear SLAs, and engineering graceful degradation paths, CTOs can protect their business from infrastructure failures without compromising regulatory compliance. Safe defaults, circuit breakers, and evidence continuity ensure that when the system inevitably fails, it fails safely, predictably, and transparently.
FAQ
What does fail-closed mean in a proof system?
It means that if the system cannot mathematically verify a proof or check its revocation status, it defaults to denying the requested action. It prevents unverified transactions from executing during an outage.
When should a verifier reject requests during an outage?
A verifier should reject requests for high-risk, restricted actions (like financial transfers) anytime it cannot confirm both the validity of the proof and the freshness of the underlying credential.
What belongs in a service level agreement for proof infrastructure?
An SLA should define acceptable uptime, maximum proof verification latency, and maximum allowable delay for fetching revocation status updates from a service provider.
How do you preserve audit evidence during downtime?
Ensure your application logging captures the request ID, the policy ID, the exact timestamp, and the specific reason for rejection (e.g., "Dependency Timeout") before dropping the request.
Can degraded mode remain compliant?
Yes, if applied correctly. Degraded mode allows low-risk, non-restricted application features to continue operating while strictly failing-closed on any actions that require verified compliance.
Which metrics matter most in real time production monitoring?
The most critical metrics are verification latency, error rates (separated by client vs. server), queue depth, and revocation status freshness.
How often should incident runbooks be tested?
Runbooks should be tested regularly, ideally through simulated failure exercises or chaos engineering, to ensure operators know how to execute the fail-closed procedures confidently.
What Comes Next
Once your production operations are resilient and your monitoring is dialed in, the next challenge is ensuring your architecture isn't permanently tied to a single vendor's proprietary format.
Interoperability in Practice: One Credential, Many Verifiers, Zero Vendor Lock-In
Want to learn more?
Explore our other articles and stay up to date with the latest in zero-knowledge KYC and identity verification.
Browse all articles